jtr1962
Storage? I am Storage!
Reading recently about CPU architecture and processor floating point performance, I was actually stoked to learn my new A10-5800K has AVX capability. It turns out AVX actually works exceedingly well in the real world. Here's Intel Burn Test with a regular (SSE?) floating point Linpack:
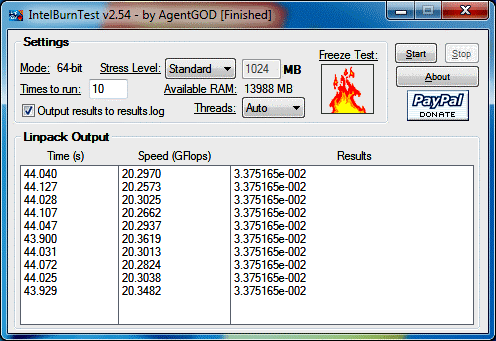
And here's the same test using AVX:

My results with AVX seemed to vary much more than with SSE. I was consistently getting about 20.3 GFlops with SSE. With AVX, I was getting anywhere from about 43 up to 46.8 GFlops. Results during any one run would be consistent, but the very next run would be different.
In a nutshell, AVX allows the CPU to do 8 double-precision (or 16 single-precision) floating point operations per clock cycle per core. This is twice the throughput of SSE. OK, two cores share a floating-point unit in Trinity, so maximum theoretical throughput in Intel Burn Test or Linx is 2x8xclock speed (4GHz in my case), or 64 double-precision GFlops. I'm actually getting more than twice the speed using AVX as opposed to SSE. And I read that Intel's new Haswell will use AVX2, which is theoretically twice the speed of AVX.
Anyway, I thought I would share these results because they're pretty amazing. 45+ GFlops may not be a speed champion by today's standards, but if I could take my new machine back in time to the early 1990s, it would have been the fastest thing around. Now if only more software would use AVX, especially train sims which by their nature do lots of FP calculations.
And here's the same test using AVX:
My results with AVX seemed to vary much more than with SSE. I was consistently getting about 20.3 GFlops with SSE. With AVX, I was getting anywhere from about 43 up to 46.8 GFlops. Results during any one run would be consistent, but the very next run would be different.
In a nutshell, AVX allows the CPU to do 8 double-precision (or 16 single-precision) floating point operations per clock cycle per core. This is twice the throughput of SSE. OK, two cores share a floating-point unit in Trinity, so maximum theoretical throughput in Intel Burn Test or Linx is 2x8xclock speed (4GHz in my case), or 64 double-precision GFlops. I'm actually getting more than twice the speed using AVX as opposed to SSE. And I read that Intel's new Haswell will use AVX2, which is theoretically twice the speed of AVX.
Anyway, I thought I would share these results because they're pretty amazing. 45+ GFlops may not be a speed champion by today's standards, but if I could take my new machine back in time to the early 1990s, it would have been the fastest thing around. Now if only more software would use AVX, especially train sims which by their nature do lots of FP calculations.